|
I am a Ph.D. student at Carnegie Mellon University working with Kayvon Fatahalian and Deva Ramanan. My research focuses on algorithms and systems for enabling efficient visual understanding. Prior to CMU, I was a Masters student at Indian Institute of Science, where I was advised by Uday Bondhugula. I worked at NVIDIA as a systems software engineer and did my bachelors at IIIT Hyderabad. I recently defended my thesis, check out my talk here. Email / CV / Google Scholar |

|
|
My research focuses on building algorithms, models and systems for efficiently training and deploying computer vision models. My work is motivated by the goal of building systems that continuously adapt and improve models with minimal human effort. The need for such systems is ubiquitous in scenarios where models are deployed in the real-world and there is a constant stream of new data being observed. For example, perception models on self-driving cars are continuously updated using data collected from the fleet of vehicles. Similarly, models deployed on personal devices like phones and household appliances are continuously personalized and customized to a user. Unlike training accurate models on fixed large-scale labeled datasets one needs to think about a range different questions such as:
|
|
|
|
|
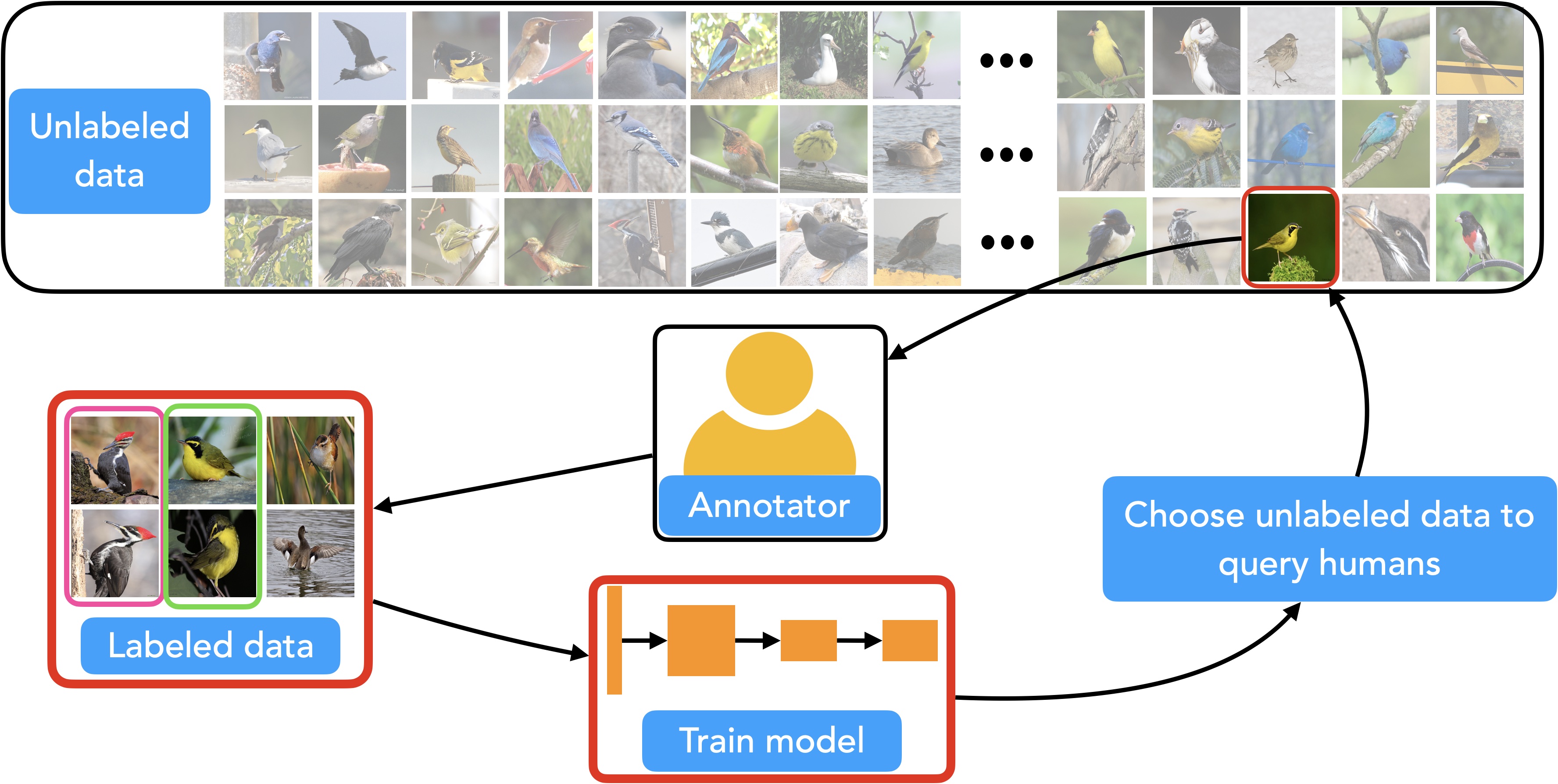
Many real-world ML deployments require learning a rare category model with a small labeling budget. Because often one also has access to large amounts of unlabeled data it is common to use semi-supervised and active learning methods to train models in this setting. However, prior work often makes two assumptions that do not hold in practice; (a) one has access to a modest amount of labeled data to bootstrap learning and (b) every image belongs to a common category of interest. In this paper, we learn models initialized with as-little-as five labeled positives and where 99.9% of the unlabeled data does not belong to the category of interest. To do so, we introduce active semi-supervised methods tailored for rare categories and small labeling budgets. We make use of two key insights: (a) We delegate human and machine effort where each is most useful; human labels are used to identify "needle-in-a-haystack" positives, while machine-generated pseudo-labels are used to identify negatives. (b) Because iteratively learning from highly imbalanced and noisy labels is difficult, we leverage simple knowledge transfer approaches to learn good features and rapidly train models using cached features. |
|
|
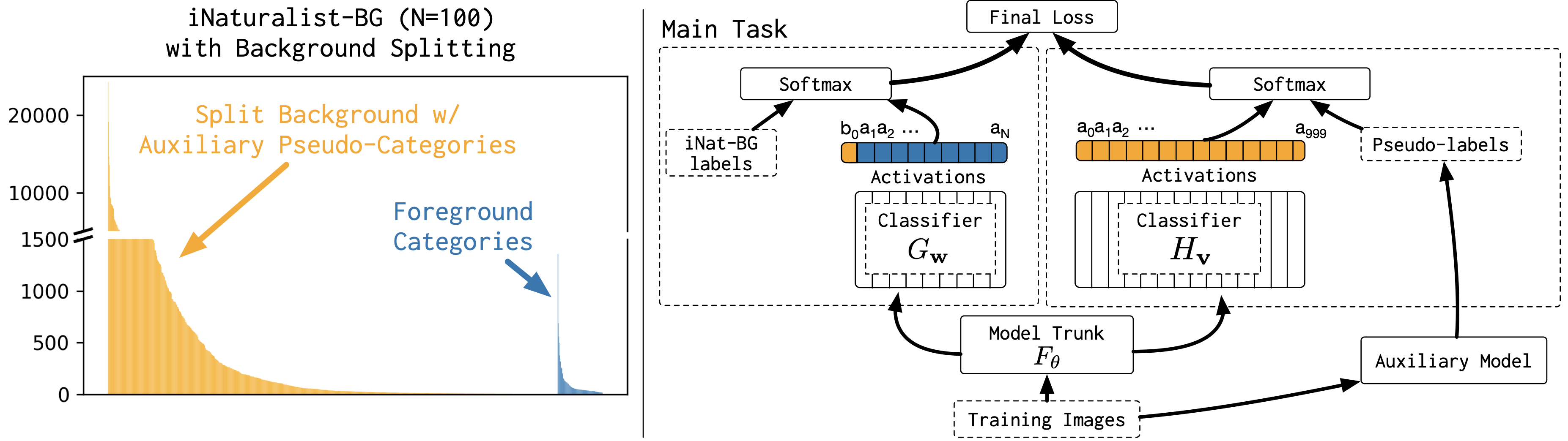
In this paper, we focus on the problem of training deep image classification models for a small number of extremely rare categories. In this common, real-world scenario, almost all images belong to the background category in the dataset. We find that state-of-the-art approaches for training on imbalanced datasets do not produce accurate deep models in this regime. Our solution is to split the large, visually diverse background into many smaller, visually similar categories during training. We implement this idea by extending an image classification model with an additional auxiliary loss that learns to mimic the predictions of a pre-existing classification model on the training set. The auxiliary loss requires no additional human labels and regularizes feature learning in the shared network trunk by forcing the model to discriminate between auxiliary categories for all training set examples, including those belonging to the monolithic background of the main rare category classification task. |
|
|

High-quality computer vision models typically address the problem of understanding the general distribution of real-world images. However, most cameras observe only a very small fraction of this distribution. This offers the possibility of achieving more efficient inference by specializing compact, low-cost models to the specific distribution of frames observed by a single camera. In this paper, we employ the technique of model distillation (supervising a low-cost student model using the output of a high-cost teacher) to specialize accurate, low-cost semantic segmentation models to a target video stream. Rather than learn a specialized student model on offline data from the video stream, we train the student in an online fashion on the live video, intermittently running the teacher to provide a target for learning. Online model distillation yields semantic segmentation models that closely approximate their Mask R-CNN teacher with 7 to 17x lower inference runtime cost (11 to 26x in FLOPs), even when the target video's distribution is non-stationary. Our method requires no offline pretraining on the target video stream, achieves higher accuracy and lower cost than solutions based on flow or video object segmentation, and can exhibit better temporal stability than the original teacher. We also provide a new video dataset for evaluating the efficiency of inference over long running video streams. |
|
|
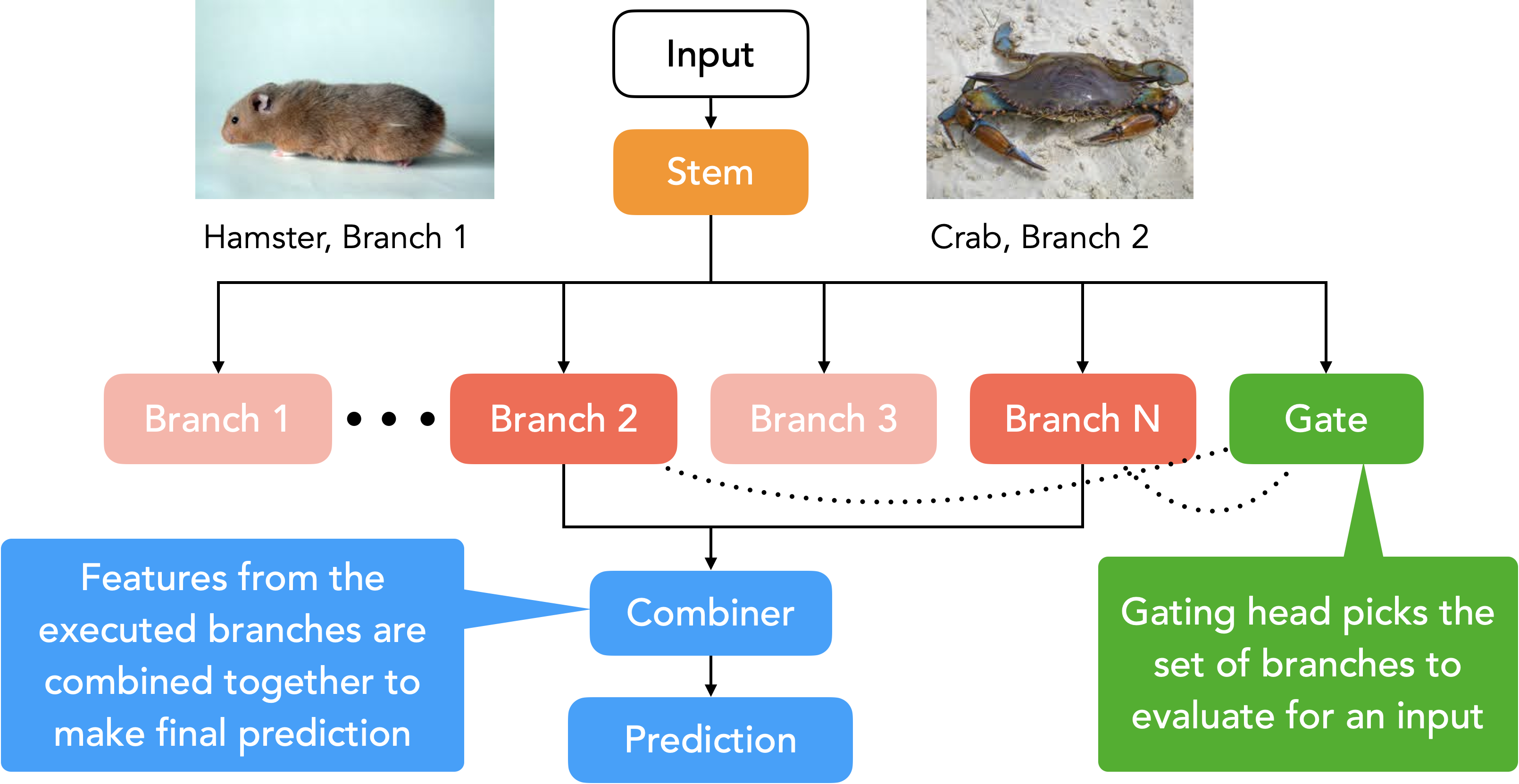
HydraNets explore semantic specialization as a mechanism for improving the computational efficiency (accuracy-per-unit-cost) of inference in the context of image classification. Specifically, we propose a network architecture template called HydraNet, which enables state-of-the-art architectures for image classification to be transformed into dynamic architectures which exploit conditional execution for efficient inference. HydraNets are wide networks containing distinct components specialized to compute features for visually similar classes, but they retain efficiency by dynamically selecting only a small number of components to evaluate for any one input image. On CIFAR, applying the HydraNet template to the ResNet and DenseNet family of models reduces inference cost by 2-4x while retaining the accuracy of the baseline architectures. On ImageNet, applying the HydraNet template improves accuracy up to 2.5% when compared to an efficient baseline architecture with similar inference cost. |
|
|
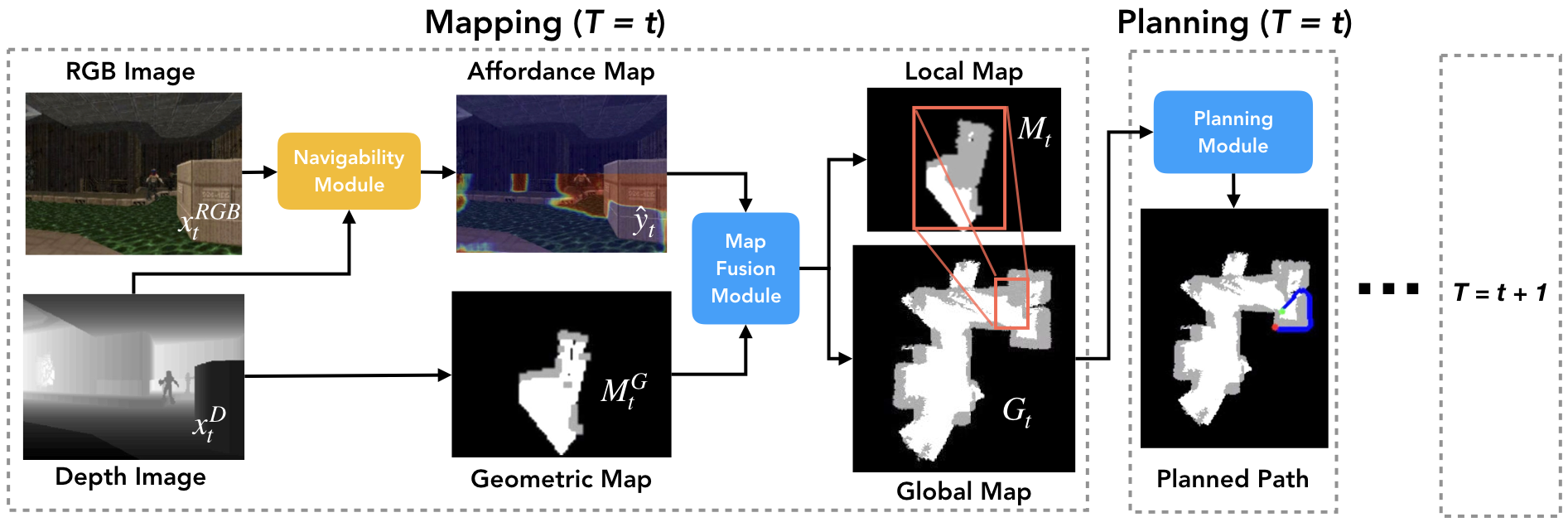
The ability to autonomously explore and navigate a physical space is a fundamental requirement for virtually any mobile autonomous agent, from household robotic vacuums to autonomous vehicles. Traditional SLAM-based approaches for exploration and navigation largely focus on leveraging scene geometry, but fail to model dynamic objects (such as other agents) or semantic constraints (such as wet floors or doorways). Learning-based RL agents are an attractive alternative because they can incorporate both semantic and geometric information, but are notoriously sample inefficient, difficult to generalize to novel settings, and are difficult to interpret. In this paper, we combine the best of both worlds with a modular approach that learns a spatial representation of a scene that is trained to be effective when coupled with traditional geometric planners. |
|
|
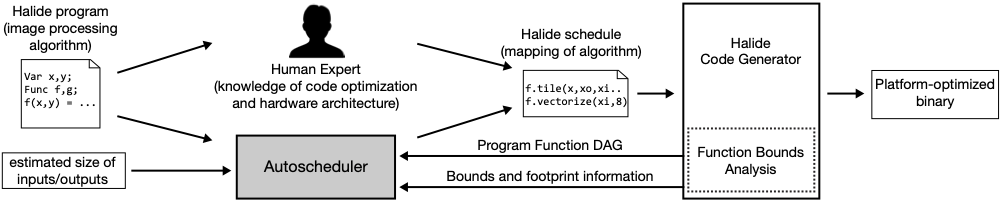
The Halide image processing language has proven to be an effective system for authoring high-performance image processing code. Halide programmers need only provide a high-level strategy for mapping an image processing pipeline to a parallel machine (a schedule), and the Halide compiler carries out the mechanical task of generating platform-specific code that implements the schedule. Unfortunately, designing high-performance schedules for complex image processing pipelines requires substantial knowledge of modern hardware architecture and code-optimization techniques. In this paper we provide an algorithm for automatically generating high-performance schedules for Halide programs. Our solution extends the function bounds analysis already present in the Halide compiler to automatically perform locality and parallelism-enhancing global program transformations typical of those employed by expert Halide developers. The algorithm does not require costly (and often impractical) auto-tuning, and, in seconds, generates schedules for a broad set of image processing benchmarks that are performance-competitive with, and often better than, schedules manually authored by expert Halide developers on server and mobile CPUs, as well as GPUs. |
|
|
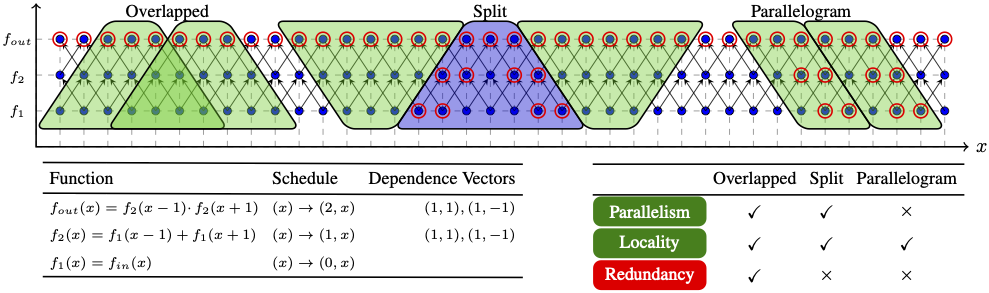
Image processing pipelines are ubiquitous and demand high-performance implementations on modern architectures. Manually implementing high performance pipelines is tedious, error prone and not portable. For my masters thesis, I focused on the problem of automatically generating efficient multi-core implementations of image processing pipelines from a high-level description of the pipeline algorithm. I leveraged polyhedral representation and code generation techniques to achieve this goal. PolyMage is a domain-specific system built for evaluating and experimenting with techniques developed during the course of my masters. |
|
|
|
Current de-facto parallel programming models like OpenMP and MPI make it difficult to extract task level dataflow parallelism as opposed to bulk-synchronous parallelism. Task parallel approaches that use point-to-point synchronization between dependent tasks in conjunction with dynamic scheduling dataflow runtimes are thus becoming attractive. Although good performance can be extracted for both shared and distributed memory using these approaches, there is little compiler support for them. In this paper, we describe the design of compiler-runtime interaction to automatically extract coarse grained dataflow parallelism in affine loop nests for both shared and distributed-memory architectures. We use techniques from the polyhedral compiler framework to extract tasks and generate components of the runtime that are used to dynamically schedule the generated tasks. The runtime includes a distributed decentralized scheduler that dynamically schedules tasks on a node. The schedulers on different nodes cooperate with each other through asynchronous point-to-point communication - all of this is achieved by code automatically generated by the compiler. |
|
|